Search and Discovery in Delivery Hero runs highly available global APIs that provide load balancing and automatic failover. We deploy our APIs in at least 2 regions from each geographic location we serve, and in 3 zones within these regions, so it’s important to be very cost-effective in the way we do this.
This post describes the steps we took to improve our GKE infrastructure, which lead us to cost reductions between 25% to 50% on the different regions our API runs in.
- Provisioning model: Using spot instances as much as possible.
- Machine type: Choosing the right machine family and type for our use case.
- Region selection: Identifying the most cost/effective regions we can use.
- App right-sizing: Configuring our pods to use the right amount of resources.
- Bin packing: Making sure our pods can fit nicely in our nodes without wasting resources.
Initial investigation
The first step in our journey began by understanding the requirements of our current infrastructure and identifying the areas we wanted to investigate for improvements.
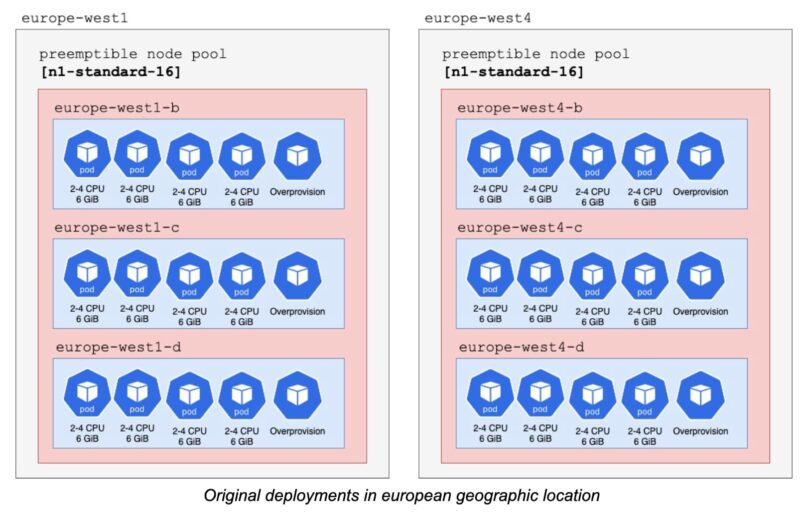
Our infrastructure needs to be error tolerant. We create virtual machine instances across three availability zones located in at least two regions per geographic location. This ensures that even if a zone or an entire region fails, our application continues to work. For example, in Europe we deploy in 2 regions: europe-west1 and europe-west4. In each of these regions, we have deployments in 3 different zones.
Our APIs also need to run in pods that can be killed at any time without impacting the system. This flexibility allows our API to survive node shutdowns without affecting our service.
Keeping this in mind, we were ready to investigate the cost/effectiveness of our current infrastructure setup.
Provisioning model
Spot VMs offer the same machine types, options, and performance as regular compute instances, but they are considerably cheaper (according to Google, up to 91% cheaper).
The critical thing to keep in mind for Spot VMs, is that they can be gracefully shutdown (with a 30 second grace period) at any point in time. So if you want to use them, you need to be sure the application is fault tolerant and can handle this kind of VM behavior.
The API we were analyzing was already fault tolerant. It was running with preemptible instances, which is the previous version of spot instances. We decided to start planning on the upgrade to spot instances to take advantage of the new features, but it wasn’t marked as a priority since spot and preemptible instances share the same cost model, so it wouldn’t have a cost impact.
Machine Type
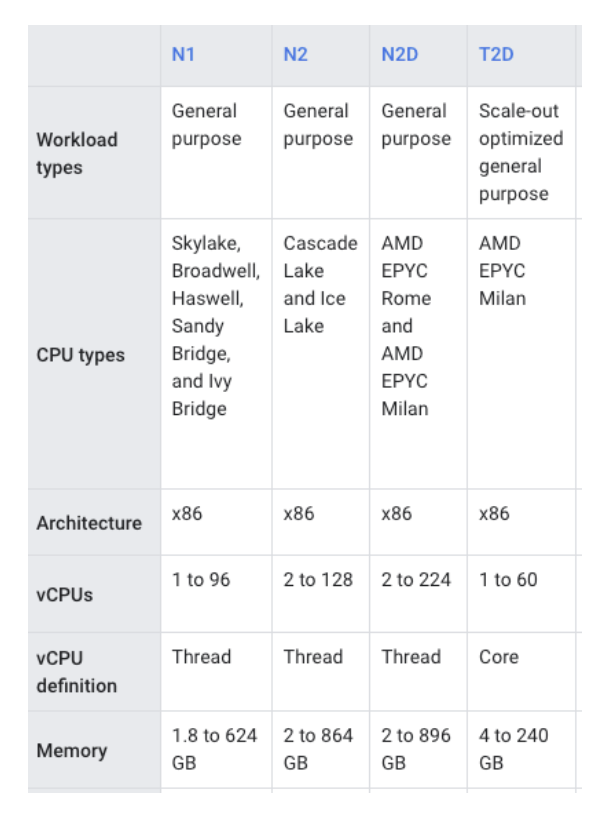
Google Kubernetes Engine offers different machine type families, and we have to make a decision on which to use based on the needs of the application.
- General Purpose: The most flexible vCPU to memory ratios, providing features that target most workloads.
- Compute-optimized: Ideal for performance-intensive workloads.
- Memory-optimized: Ideal for workloads that require higher memory to vCPU ratios.
- Accelerator-optimized: Optimized for massively parallelized Compute Unified Device Architecture (CUDA) workloads, such as machine learning (ML) and high performance computing (HPC).
In our case we know our API falls in the General Purpose category: it is neither memory or vCPU intensive, and it requires a flexible vCPU to memory ratio. Actually, it was running already on N1 instances.
With this in mind we proceeded to find the right machine type from the new options available in this family: N2, N2D or T2D.
The main difference between them is the processor (each processor comes with a different set of features) and the vCPU to memory ratio capability.
To know which machine type worked best for our use case, we created clusters for N2D and T2D machine types and load tested our API against them. We then compared the results between them and against the N1 machine type we already had in production.
With this exercise, we were able to see how our application performed under real stress using each of the different machine types. We compared values such as:
- Latency of the responses (p90 /p95 / p99)
- Success rate
- Ability to scale up and down quickly with demand.
- Total vCPUs used during the load test
The results were very positive, we noticed that we could run on both N2D and T2D clusters the same load we did on N1, but using around 35% less vCPU in N2D and 45% less in T2D. Both without having a negative impact on latency or errors.
Region selection
The three main things we analyzed when selecting which regions to deploy our service at were: latency, machine availability and cost.
To evaluate latency, we analyzed the location of our clients and the location of our upstream and downstream dependencies. This gave us a good picture of which regions might work well for us. We then created clusters on those regions, deployed our API there and performed load tests.
During the load test we observed the different latency values we got from each region. This gave us clear evidence of how each region would perform in production for our API, and helped us decide which ones we could use and which ones we should avoid.
We then used Google Cloud Pricing Calculator to get an estimate of the different costs each machine type had on each region. It is important to know that not all machine types are available in all regions, and that the price of the same machine type may be different between regions.
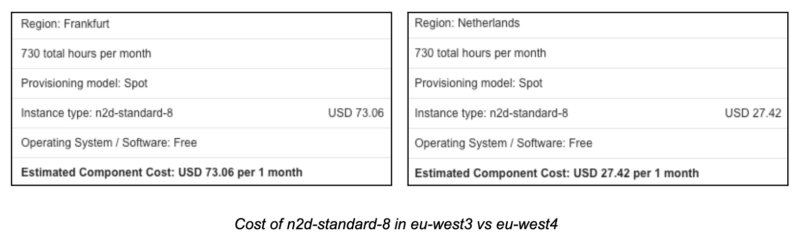
For example, while analyzing the price for the same N2D instance in different european regions, we found important differences. The region that reported the best price was europe-west4, where each instance costs $27.43. In contrast to europe-west3, where the price for the same instance is $73.06.
During the time of our evaluation, T2D was available in fewer regions than N2D, so it limited us on where we could deploy this instance type. It was also available in regions with higher costs, making it less appealing cost-wise.
App right-sizing
According to Google’s announcement, N2D offers 39% performance improvement on the Coremark benchmark compared to comparable N1 instances.
By upgrading from N1 to a new generation of machine types, our goal was to squeeze more juice out of the more performant vCPUs. We expected to deploy pods with less vCPU and to increase the vCPU threshold value used by our horizontal pod autoscaling (HPA), while still performing the same or better.
To determine the best values we could set for our resource configuration, we performed load tests with different vCPU values and different HPA configurations, while monitoring our latency and error rate metrics.
In the end we managed to incorporate these changes:
- We increased our HPA threshold from 35% to 50% since the pods with more performant vCPU were able to get more work done.
- We reduced the vCPU requests value from 2 to 1 because with a more performant machine type we were able to run our pods with less vCPU.
- We reduced the memory requested by our pods from 6GB to 4GB, because we noticed we were already overprovisioning it, by checking the pod’s dashboards.
So we effectively were able to cut our workload’s vCPU requested value by 50%, and our memory requested value by 33%.
Bin packing
Once we had the right configuration of vCPU and memory for our pods, we needed to make sure we had the right node configuration, so that pods could fit nicely in them without wasting resources.
This is accomplished by bin packing.
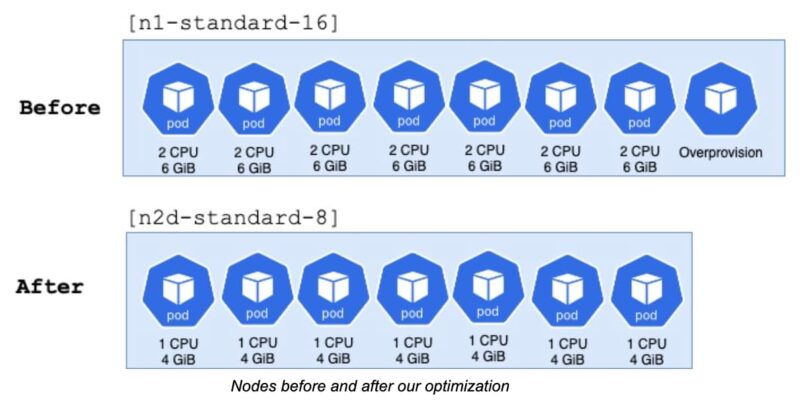
After optimizing the resources of the pods on the step before, we defined we required 1 vCPU and 4GB of memory for each one of them.
We chose to use nodes with n2d-standard-8 machine types. This meant that each node had a total of 8 vCPU and 32GB of memory.
With this configuration, we were able to fit 7 pods in the nodes, using 7 out of 8 vCPUs and 28 out of 32GB of memory. Keeping in mind some vCPU and memory are reserved and not available for our pods, this machine type was a very good match for our needs.
As an added bonus, with the new machine types we managed to remove the overprovision pods that we used in our N1 nodes. Their purpose was to have resources pre-allocated to quickly provision new pods when needed, and reduce the waiting time for new nodes to be ready.
Since the new machine types were more performant, they managed to handle more load effectively and the wait time for new nodes to be available while scaling up didn’t cause us any issues.
Cost evaluation
Once we had everything in place, we knew we had the right machine type and that it would perform well against our API, but we still needed to validate that it was also going to be less expensive than our current setup. To validate this we followed these steps:
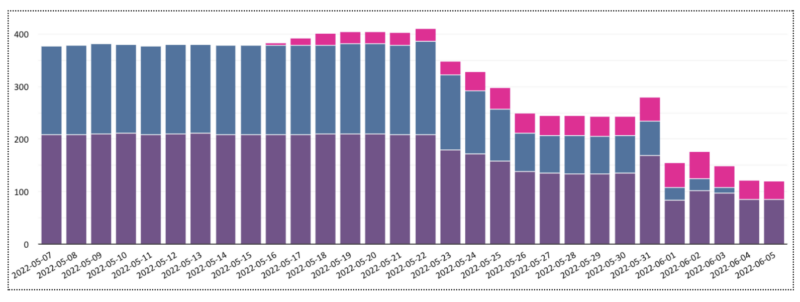
At the beginning, we had 2 clusters using the old machine type n1-standard-16. Traffic was being load balanced between them 50 / 50. They’re represented in the image above with blue and purple colors.
We then added a third cluster with the new machine type n2d-standard-8, shown above in pink. We slowly sent all traffic from the purple n1 cluster into the pink n2d cluster. Eventually, only the blue n1 and pink n2d clusters were serving traffic. The purple n1 cluster was idle.
At this stage, we were able to notice that the pink n2d cluster had a very significant cost reduction over the original purple n1 cluster. So we continued with the deployment.
The next step was to replace the machine type from the purple n1 cluster with the new n2d-standard-8 machine type. At this point the purple n1 cluster was not serving traffic, only blue n1 and pink n2d were serving traffic.
Once the purple n1 cluster was converted into a purple n2d cluster, we switched all traffic from the blue n1 cluster into it and proceeded to remove the blue n1 cluster from our infrastructure.
In the end, we were left with the purple and pink clusters, both using n2d-standard-8 machine types, and both showing a significant cost reduction from our original setup.
Conclusion
Optimizing the Google Kubernetes Engine infrastructure we use to run our application required investigation to understand our system needs, several tests to validate the performance of the different alternatives we had, and an evaluation in production to validate cost expectations.
The main aspects we focused on were:
- Making sure our application is fault tolerant and can make use of the more economic spot instances.
- Upgrade to a new generation of machine types, to have less but more powerful resources.
- Find the best region we can use to deploy our service that provides good latency and lower costs.
- Fine tune our application to use the right amount of request resources and autoscale configurations.
- Pack our application properly so that pod requested resources fit in the node resources.
Running actual load tests in different clusters was the key to know how the system will actually perform on each of them. This helped us select the most performing regions and machine types, ruling out the slowest or more inefficient ones, based on the actual metrics gathered against the real use case: our API.
Once the best performing candidates were selected, using them in production for a time-boxed period of time, validated if our cost projections were real, and allowed us to make a final decision on which region and machine type to use, based on real performance and cost metrics.
If you like what you’ve read and you’re someone who wants to work on open, interesting projects in a caring environment, check out our full list of open roles here – from Backend to Frontend and everything in between. We’d love to have you on board for an amazing journey ahead.