Leveraging the Feature Store for Fast-Tracking ML Model Development
13 June 2023At Delivery Hero, data science and machine learning play an essential role in personalizing the experience of our users. To enhance the efficiency of the feature engineering process, the ML Platform team has designed and developed a Feature Store solution that empowers data scientists to efficiently create, monitor and serve features for their machine learning models.
As stated in the article Personalization Journey @ Delivery Hero, our cross-functional teams at Data & ML product line are dedicated to building a great personalized experience for our customers. We accomplish this by focusing on different topics including ranking, recommendation systems, customer segmentation, incentives, and fraud detection.
To support those efforts and improve the long-term efficiency of our teams, the ML platform team has a mission of promoting good practices and offering solutions for common challenges faced by data scientists and ML engineers.
Feature engineering is a challenging task that plays a vital role in achieving good results in data science and ML projects. The most common way of managing features used to be maintaining feature codes as part of the model repositories. While this approach may work for small teams with a limited number of models, it becomes inefficient as the number of teams and projects scales up.
With that approach, features couldn’t be easily reused across projects leading to the redundant creation of similar features in different repositories and duplication of efforts. Apart from that, there was no standardization for feature building and quality leading to a lack of consistency and increased data quality issues.
In order to improve this process, the ML platform team at Delivery Hero has designed and developed a Feature Store solution that acts as a central component to empower data scientists and ML engineers to efficiently create, monitor and serve features for their machine learning models.
Workflow
To promote consistency and efficiency across teams, we have implemented a shared feature repository that is accessible to all Feature Store users. This repository serves as a centralized hub where users can not only reuse existing features but also contribute by adding new ones.
Throughout the development cycle, our data scientists have tooling that facilitates the creation, testing, and refinement of feature codes. They can efficiently generate feature data within a staging environment, which provides a safe and isolated space for developing new features without impacting the production environment.
Data scientists contribute to the shared feature repository through pull requests that are reviewed by their peers to ensure code consistency and quality. Once the feature codes are approved and merged into the main branch, new features are seamlessly integrated into the feature pipelines that operate in the production environment.
Architecture
The following image shows a high-level diagram of the feature store architecture.
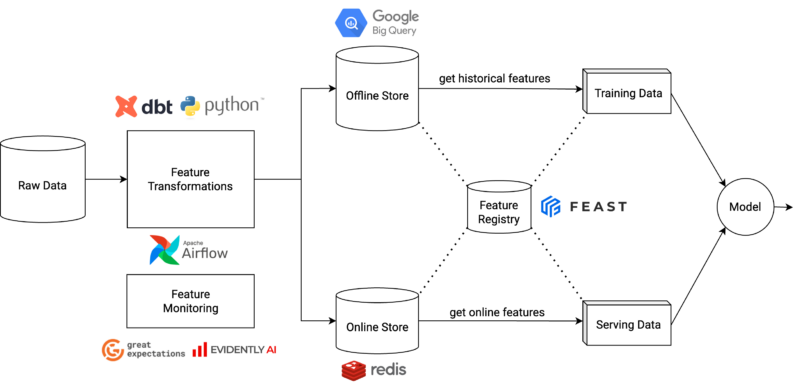
This architecture can be logically divided into offline and online components. Offline components are used to transform raw data into feature data that is used for model training, whereas online components are used to materialize feature data into a low-latency database that is only used for model inference. Both modules can be used independently, which allows the gradual integration of the data science models with the feature store.
Feature Transformations
Our solution provides a comprehensive toolkit for transforming raw data into features. Data scientists have the flexibility to write feature transformations using either SQL or Python.
- SQL transformations: Data scientists leverage the open-source package dbt for creating feature transformations. dbt is used widely in several teams at Delivery Hero and it offers several benefits for our needs. Its SQL-based approach aligns with our existing data infrastructure and allows our data scientists to leverage their SQL skills to create feature transformations. Its seamless integration with BigQuery ensures scalability, enabling us to handle large datasets effectively. Its proven track record provides us with confidence in its reliability and effectiveness. Its compatibility with various platforms gives us the flexibility to work with diverse data sources and adapt to future technology changes.
- Python transformations: Data scientists can also use an in-house implementation for creating transformations using the Python language. All they need to do is add modules using a standard function signature that receives a context parameter and returns a dataframe. Those modules are recognized and run as part of the feature pipelines. This component is particularly well-suited for handling more complex operations which need the versatility of a programming language like Python. It relies on Kubernetes for seamless execution and scalability.
To promote collaboration and reusability, we have organized features by business contexts such as vendors, customers, and products. This approach aims to foster collaboration and break down silos across teams.
Feature Monitoring
Our solution offers components to proactively detect feature quality issues and feature distribution shifts.
- Feature Quality Checks: This component provides data scientists with the ability to configure expectations for their data and validate the feature data produced by the Feature Store. To simplify the process, we have developed a wrapper package built on top of the Great Expectations that makes it easier for users to define and set their desired data quality standards.
- Feature Drift Detection: This component is built upon the EvidentlyAI package, empowering data scientists to identify sudden shifts in feature distributions that can have a significant impact on the performance of data science models. With this component, users have the flexibility to define drift configurations based on their needs by setting up drift algorithms to be used and their parameters.
Additionally, our solution offers a command-line interface (CLI) that enables users to run their monitoring modules effortlessly and have access to validation reports.
Feature Pipelines
Feature pipelines serve as the orchestrators for executing transformation and monitoring tasks. They are seamlessly scheduled and managed by Airflow. Our solution leverages the Data Hub platform which offers Airflow as a service for teams at Delivery Hero.
One powerful feature of this system is its ability to dynamically generate Airflow DAGs based on the content available in the shared feature repository, eliminating the need for direct intervention from data scientists. For instance, each dbt model from a dbt project is mapped to an Airflow task from an Airflow DAG. This automation streamlines the process and ensures that the most up-to-date features are incorporated into the pipelines. In addition, users have the flexibility to backfill tables for a specified historical period using a configuration file.
All Airflow DAGs are integrated with Slack, enabling notifications to be sent directly to relevant stakeholders in the event of failed feature transformations or identified data quality issues, fostering efficient teamwork and enabling prompt responses to any issues or updates. Additionally, our solution utilizes a metadata tracking server to store comprehensive reports associated with the feature pipelines, including quality and drift reports.
Feature Serving
The offline store serves as the repository for historical features, which are primarily used for model training. BigQuery has been used as the offline store for some reasons. It’s a highly scalable solution that ensures reliable performance for massive volumes of data. With its SQL-based interface, data scientists can easily manipulate and extract insights from the data. Its serverless nature abstracts away the underlying infrastructure management, reducing the maintenance overhead for the ML platform team.
On the other hand, the online store is primarily used for storing features to be fetched from the model serving APIs. Teams at Delivery Hero have very tight restrictions regarding latency for model serving applications and an online store must provide low-latency access to retrieve features. This is a decisive factor when choosing an online store. Redis has been used as the online store since it’s an in-memory data store known for its exceptional performance.
Feast is used for registering features in a shared registry, materializing data from the offline store to the online store, and providing a Python SDK to fetch features for model training and serving. Considering our tight latency requirements, we had to create some custom implementations for reducing latency in fetching features from the online store.
Conclusion
A centralized feature store promotes increased feature reusability across projects. By providing a shared feature repository, data scientists can leverage existing features, eliminating redundant creation of features and duplication of efforts. This reduces the effort required for creating new data science models from scratch.
The feature store has also established standardized feature generation and quality processes. With a unified framework, data scientists can follow consistent practices for creating and validating features, resulting in more robust and reliable machine learning pipelines. Apart from that, all feature pipelines are automated and this also reduces the engineering efforts for data scientists and data engineers working on application teams.
If you like what you’ve read and you’re someone who wants to work on open, interesting projects in a caring environment, check out our full list of open roles here – from Backend to Frontend and everything in between. We’d love to have you on board for an amazing journey ahead.