Don’t Worry, We Got You: Personalised Model
15 August 2023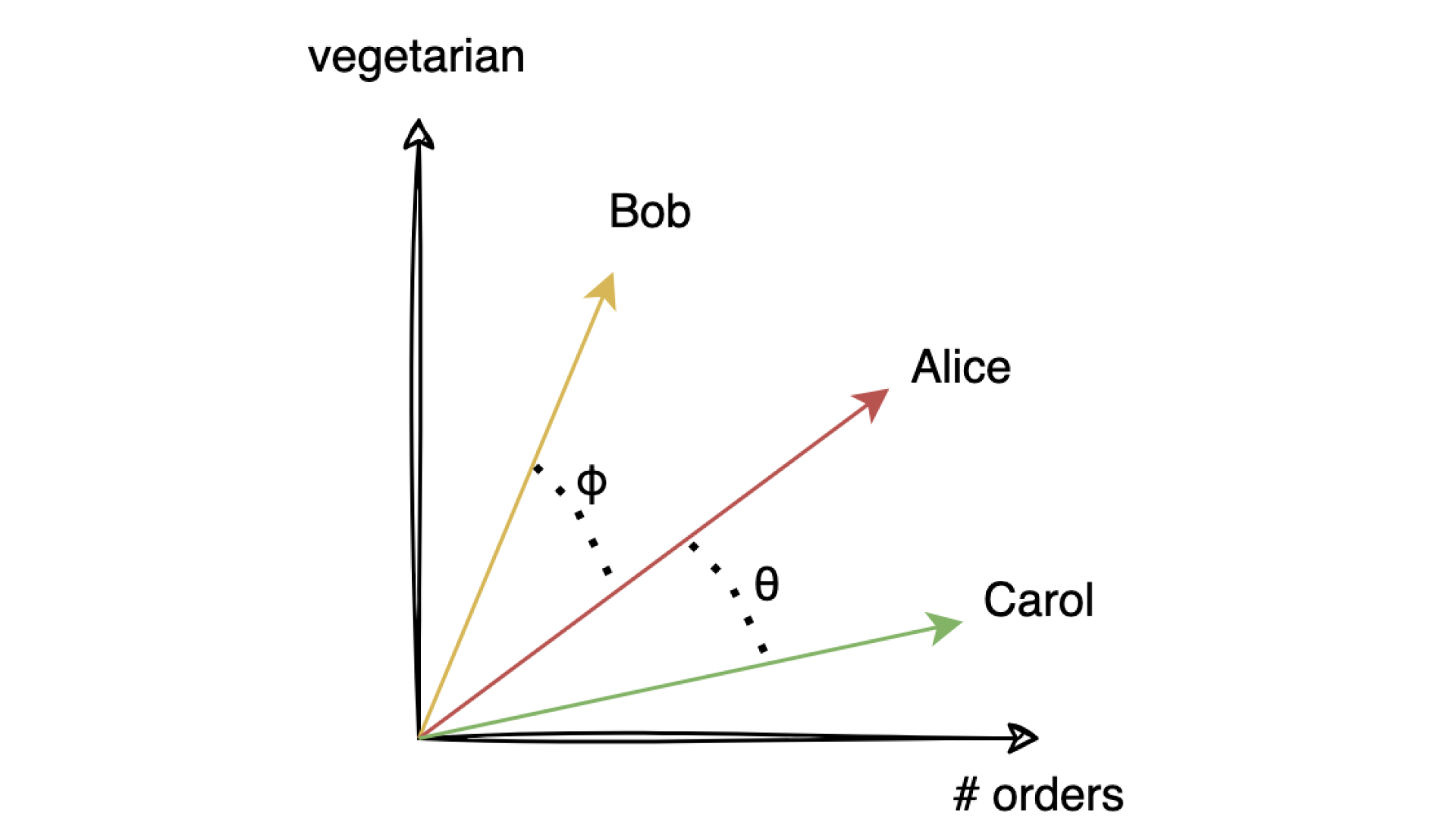
Previous blog posts have discussed capturing new customers onto our platform, but that’s one step along the customer journey. We aim to retain these customers and deliver to them the best delivery experience imaginable.
Once we know a customer’s behaviour based on their interactions with our system, we try to provide more fine-tuned recommendations, tailored to individual tastes and preferences. The more we know about you, the better our recommendations get. The “know you” part is where the whole data science magic happens. Data Scientists leverage both explicitly shared feedback and implicitly deduced behaviours to power such models.
Ranking and personalisation
Personalisation through customer data
To provide the best personalised experience for customers, we use data from the customer interactions with the app. Obtaining information about what a customer prefers is most easily done when the customer gives direct feedback, typically by giving a rating out of 5 or a thumbs up. This is called explicit feedback since we know for sure whether a given customer liked or disliked a given restaurant. This gives a very strong and powerful signal, however, the downside is that very few customers leave reviewers which presents a problem. Go to your favourite youtube video and compare the view count with the number of thumbs up and it’s often less than 1% of the total view, so even though it is a very strong signal, it represents only a very small subset of customers and can only provide very limited information about the whole customer base.
Instead, we rely primarily on implicit feedback. Implicit feedback is based on the customer interacting with the app and inferring information based on their interactions. For example, a very strong implicit signal is when a customer places an order as even if the customer doesn’t give us feedback about the order, we know that the customer preferred something about the vendor enough to order from them. If a customer orders repeatedly from the same vendor, that tells us that the customer likes this vendor, even if they haven’t told us that directly. This feedback isn’t just limited to orders and we use numerous other interactions to derive implicit feedback, such as the type of food ordered, vendors interacted with but not explored, and time of day to name a few.
As customers interact with our platform more and more, we are able to create a better profile of their behaviours and their preferences and use that data to provide personalised recommendations to them.
Identifying similar customers
Personalised recommendations come in many forms and one we utilise is finding similar customers and recommending based on these similarities. This type of recommendation is very common, often coming under the banner of “customers similar to you also bought” or “customers who like X also like Y”. Movies are a good analogy for recommendations where if Alices likes movies A,B,C and Bob likes movies A and C, movie B would be a good recommendation for Bob.
However, we cannot just blindly apply these principles to food delivery as a customer’s food preferences are often tied to cultural and dietary preferences and food is a very personal experience so we need to be careful to recommend things we know for sure the customer likes. Consider the case of food preferences where we have vegetarian and non-vegetarian customers. A non-vegetarian customer will eat at restaurants with both vegetarian and non-vegetarian food and if we find this customer is similar to a vegetarian customer, it would give a negative experience to recommend those vendors to vegetarian customers as we may recommend non-vegetarian vendors which can lead to a negative experience.
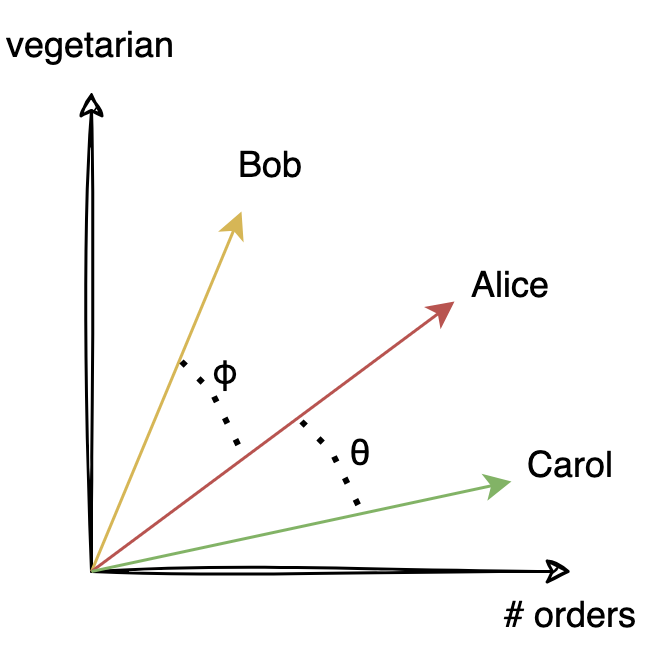
To represent this similarity relationship mathematically, consider the above diagram which presents an abstract representation of how many orders (x-axis) and how vegetarian (y-axis) a customer has. We want to find the customer who is most similar to Alice between Bob and Carol. We represent each customer as a vector in this space and use the angle between the different vectors to determine closeness – this is known as cosine similarity. This similarity between two customers tells us how close they are to each other and whether we can use data from them to recommend.
We use this similarity to create a score for each vendor which can be expressed as
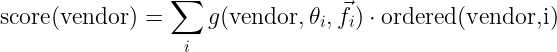
where for a given customer we calculate a score for each vendor. The summation is over all the other customers (in practice we limit this to only the most relevant) and the ordered function expresses whether the given vendor had been ordered by that customer. The function “g” is an arbitrary function that assigns a score to a given vendor given the similarity of the customer with the target customer given feature vector f. There are numerous choices for this function and the specific choice depends on extensive testing. The vector f is a feature vector and contains other relevant features we want to include in the model.
This score is calculated for every vendor that is available for a given customer and then sorted to give a recommended list of vendors. An advantage of this model is that it is simple to understand as customers who are similar will be weighted more heavily versus those who are dissimilar. This gives an easy interpretation of why we are recommending specific vendors to customers. As mentioned above, we can’t just naively present this ranking and there is additional business logic that is added atop of this list to take into account additional business rules.
Going further – collaborative filtering
The model described above performs well, however, there is a lot of flexibility in defining the way of assigning a score. Additionally, the above model does not scale well as we need to calculate, for each customer, a score for each vendor by summing over all similar customers. At Delivery Hero’s scale, with millions of customers and thousands of available vendors, it becomes resource intensive as more and more features are added. To combat this, we also utilise another common approach for recommendations: collaborative filtering.
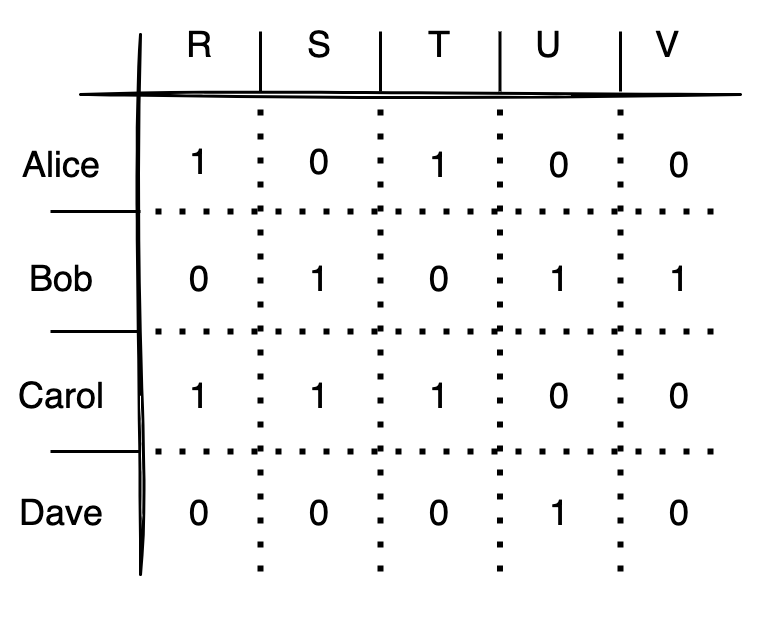
Collaborative filtering works by constructing a customer-vendor matrix (see figure) which encodes information about each customer’s interactions with a given vendor while vendors with no interactions are assigned 0. In the above example, we have just used a boolean representation where we are only considering if the customer has ordered from a given vendor, independent of how many times they might have done so. This matrix can then be factored into smaller matrices, known as embeddings, which can be multiplied together to give a score for each vendor for each customer.
This approach is beneficial for us as matrix factorisation can be done very quickly, reducing training time, and allows for more rapid experimentation of the interaction values. For example, we can embed directly into the interaction the number of orders, vegetarian scores, ratings, or any other features we have determined are valuable. Another big benefit of this approach is the creation of embeddings, which are mathematical representations of customers and vendors. These embeddings can be used as input features for other machine learning models across Delivery Hero.
Conclusion
In this blog post, we have presented a basic overview of the types of personalisation models we use within Delivery Hero to deliver the best restaurant recommendations possible. We are on a never-ending path to improve our models and gain more insight into customers’ preferences to enhance all our machine learning models.
One topic that we didn’t discuss, but is very important, is the evaluation of recommendation models. It is a complex topic and the subject of a future blog post so check back soon for more details!
If you like what you’ve read and you’re someone who wants to work on open, interesting projects in a caring environment, we’re on the lookout for Data Science Managers, Associate Data Scientists and Machine Learning Engineers. Check out our full list of open roles here – from Backend to Frontend and everything in between. We’d love to have you on board for an amazing journey ahead.